Health Insurance Cross Sell Prediction
Cross selling is the process of offering an existing customer a product that is similar or compatible to the product that they already purchased. Acquiring a new customer is harder than retaining existing customers, which makes customer relationship a very important aspect for any business.
Cross selling can be an effective method to strengthen the relationship with the customer while also boosting the revenue of the business. When rightly done, it can:
- improve the customer’s experience with the existing product, or
- solve some new problems for them.
Planning cross selling strategy It is important to know which customer might be interested or uninterested in a product while planning the cross selling process. This helps to:
- avoid any potential negative effects on the customer relationship due to the cross selling advertisement.
- make efficient use of the communication and marketing efforts.
So we will use the data of past health insurance policy holders of our client to build models that can classify a customer as ‘Interested” or “Not interested” in the vehicle insurance. So that the company can plan their marketing and communication strategy accordingly.
Overview
- All the features in the dataset (including Age, Annual Premium amount, Vehicle Age etc.) are carefully studied.
- The Response (Interested, Not interested) classes were highly imbalanced. SMOTE was used to balance them.
- Logistic Regression, Decision Tree Classifier, Random Forest Classifier and XGBoost Classifier were built.
- The performances of these models are evaluated and compared.
- Python libraries such as Pandas, Matplotlib, Seaborn, Numpy, Imbalanced-learn, Scikit-learn and XGBoost are used.
View the complete notebook HERE
Objective
The aim is to predict whether a health insurance policy holder will be “Interested” or “Not interested” in the company’s vehicle insurance.
Data Preparation
- There were no missing values to deal with in the dataset.
- The interest response classes were heavily imbalanced. SMOTE method was used to synthesize new observations to balance the classes.
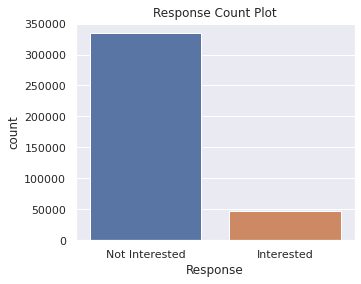
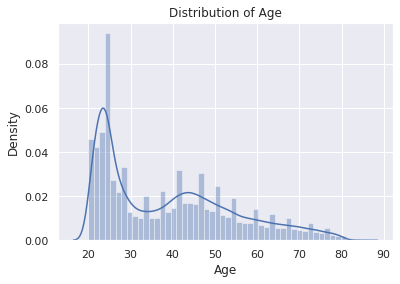
Exploratory Data Analysis
- Count of data across categories of various features was studied.
- Distribution of numerical features was visualized.
- Relationships between the dependent variable and features was studied.
- Correlation heatmap was plotted to look for multicollinearity.
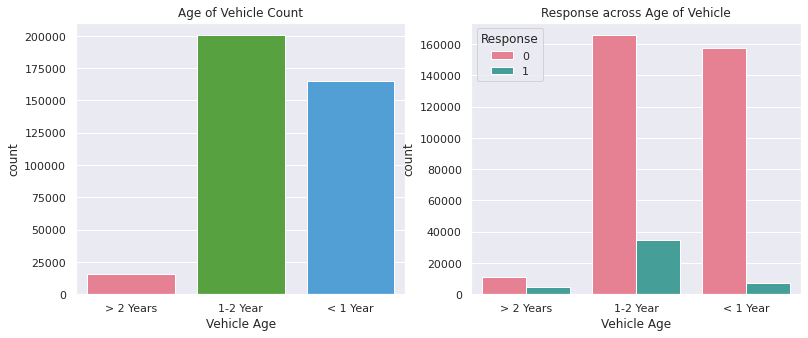
Models
Logistic Regression Model
- The dataset was split into training and testing dataset and scaled.
- The model was fit and the target variable predictions were made.
- Hyperparameter tuning was done using GridSearchCV.
- Model performance was evaluated using Accuracy, Precision, Recall and F1 score.
- ROC curve and confusion matrix was constructed.
# train test splitting
X_train, X_test, y_train, y_test = train_test_split(X_new, y_new, test_size = 0.3, random_state = 23)
# standardising the data
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import GridSearchCV
# hyperparameter tuning and crossvalidation
parameters = {"penalty":['l1', 'l2', 'elasticnet', 'none'],"max_iter":[100,200,300]}
clf = GridSearchCV(LogisticRegression(), param_grid = parameters, scoring = 'accuracy', cv = 3)
# fitting the model
clf.fit(X_train, y_train)
# class prediction on training and testing datasets
y_pred_lr = clf.predict(X_test)
y_train_pred_lr = clf.predict(X_train)
# probability prediction on training and testing datasets (only using probabilities of positive class)
y_prob_lr = clf.predict_proba(X_test)[:,1]
y_train_prob_lr = clf.predict_proba(X_train)[:,1]
# performance evaluation
print(classification_report(y_test, y_pred_lr))
print(classification_report(y_train, y_train_pred_lr))
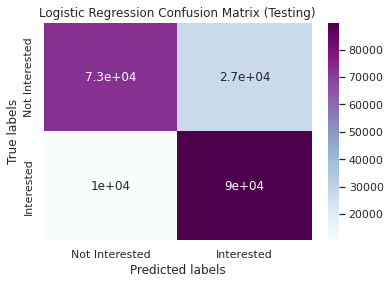
Performance metrics for Testing dataset
Accuracy : 0.81
Precision: 0.76
Recall: 0.89
F1-Score: 0.82
Area Under the ROC Curve: 0.88
Receiver operating characteristic (ROC) Curve
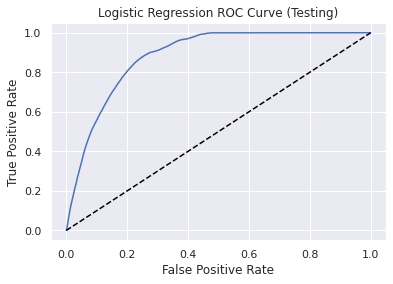
Confusion Matrix
Decision Tree Classifier
- GridSearchCV was used for hyperparameter tuning and cross validation.
- The model was fit and the target variable predictions were made.
- Model performance was evaluated using similar performance matrix.
from sklearn.tree import DecisionTreeClassifier
dtmodel = DecisionTreeClassifier(criterion = 'entropy', random_state = 32)
# hyperparameter tuning and cross validation
parameters = {'max_depth':[7,9,11], 'splitter':['best','random'], 'min_samples_split':[2,4]}
decisiontree = GridSearchCV(dtmodel, param_grid = parameters, scoring = 'accuracy', cv = 3)
# fitting the model
decisiontree.fit(X_train, y_train)
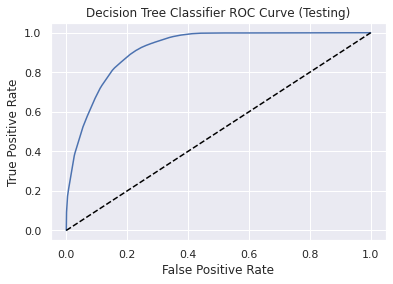
Performance metrics for Testing dataset
Accuracy : 0.84
Precision: 0.79
Recall: 0.91
F1-Score: 0.8
Area Under the ROC Curve: 0.91
Receiver operating characteristic (ROC) Curve
Confusion Matrix

Random Forest Classifier
- The model was fit and the target variable predictions were made.
- Model performance was evaluated using similar performance matrix.
- Important features were calculated.
from sklearn.ensemble import RandomForestClassifier
randomforest = RandomForestClassifier(random_state = 71, max_depth = 11, min_samples_split = 4, n_jobs = -1, criterion = 'entropy', n_estimators = 100)
# fitting the model
randomforest.fit(X_train, y_train)
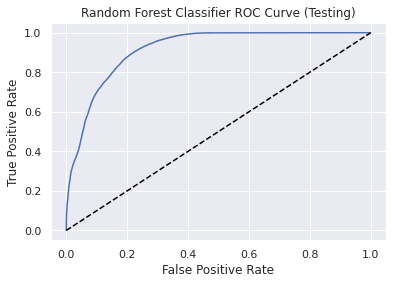
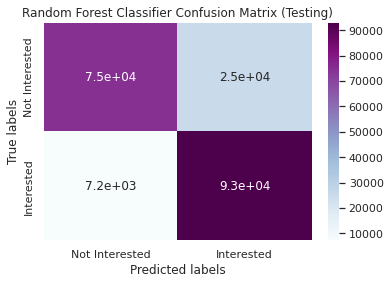
Performance metrics for Testing dataset
Accuracy : 0.83
Precision: 0.78
Recall: 0.92
F1-Score: 0.85
Area Under the ROC Curve: 0.91
Receiver operating characteristic (ROC) Curve
Confusion Matrix
Feature Importance
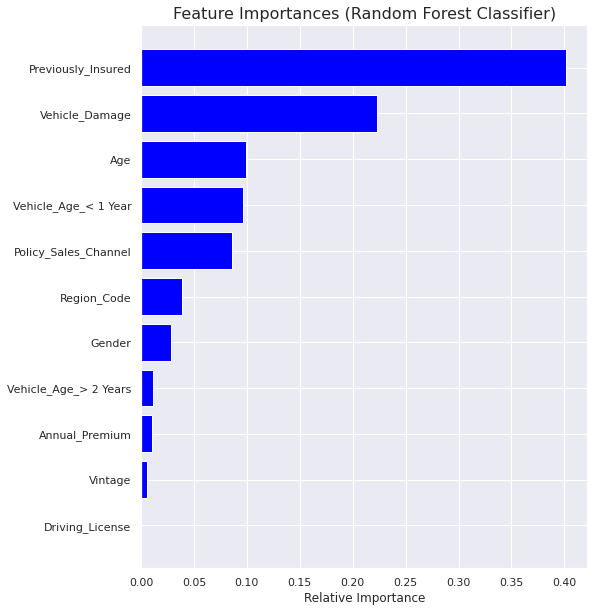
XGBoost Classifier
- The model was fit and the target variable predictions were made.
- Model performance was evaluated using similar performance matrix.
- Important features were calculated.
from xgboost import XGBClassifier
xgb = XGBClassifier(seed = 12, use_label_encoder = False, objective = 'binary:logistic',
subsample = 0.9, colsample_bytree = 0.5,
max_depth = 7, learning_rate = 0.5, gamma = 0.25, reg_lambda = 1)
# fitting the model
xgb.fit(X_train, y_train)
Performance metrics for Testing dataset
Accuracy : 0.89
Precision: 0.9
Recall: 0.88
F1-Score: 0.89
Area Under the ROC Curve: 0.97
Receiver operating characteristic (ROC) Curve
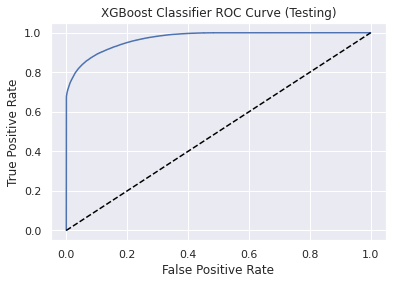
Confusion Matrix

Feature Importance
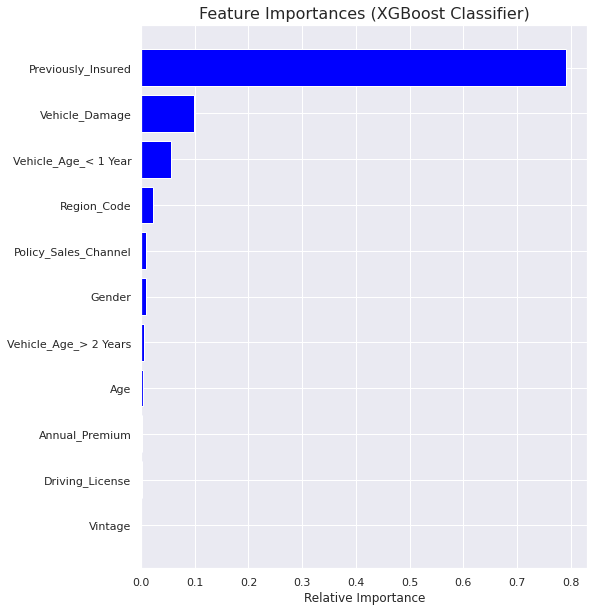
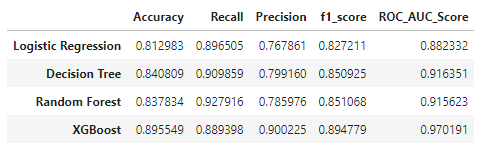
Model comparison
Conclusions
EDA
- Customers aged between 30 to 50 are more interested in the vehicle insurance compared to the youngsters.
- The chance of customers with out Driving License being interested in buying insurance is very low.
- There is very low chance that a person who is previously insured is interested in the insurance.
- Most of the customers pay annual premium below 100,000.
- Number of men with driving license is higher than women in the data. This further results in the number of interested customers being higher in men than women.
- Most of the customers whose vehicle wasn’t damaged before are not interested in the insurance
- There is no perfect multicollinearity between any of the independent variables.
Models
- XGBoost Classifier stands out with an accuracy score of 0.89 and area under ROC curve of 0.97.
- The Random forest and decision tree classifier has almost similar performance (in terms of accuracy and ROC score).
- The logistic regression model is the worst of them all (by a small margin).
- There are some differences in the feature importances of Random Forest model and XGBoost model. But ‘Previously Insured’ followed by ‘Vehicle Damage’ are the most important features for both.